
Private AI with Ollama
Do you want to take full advantage of generative AI but are wary of sharing your private information with companies like Open AI, Google, or Microsoft? There is a way out: Use your personal computer and open-source software.
Step 1: Install Ollama
☕ Skip this step if you have the latest version of Ollama installed on your machine.
Go to the ollama.com, download and install Ollama on your computer. It is available for macOS, Linux, and Windows.
📝 Ollama is an open-source application that allows users to run large language models locally. It was developed by Michael Chiang and Jeffrey Morgan based on the Llama.cpp, a C++ library written by Georgi Gerganov. You can download the Ollama source code from Github: github.com/ollama/ollama. The application is written in C and Go.
Once you have installed Ollama, you can verify it is running by using the following command:
ollama --versionStep 2: Download Latest Model
To run Ollama, you need at least one model. Go to ollama.com/library, and you will see a list of available models. The most recent models will be at the top. When this article was published, the latest model was llama3.1. Click on the model name to find out more details.
Llama 3.1 is a new model from Meta, available in parameter sizes 8B, 70B, and 405B. Use the drop-down list to select the model you want to use, and on the right, you will see the command to download and use the model.
For example, if you select “llama 3.1 70B”, the command to download will look like this: ollama run llama3.1:70b. If you do not know which one to use, start with the smallest one. Go to the command line and enter the command:
ollama run llama3.1:8b
pulling manifest
pulling 87048bcd5521... 100% ▕██████████████████████████████████████████████▏ 4.7 GB
pulling 8cf247399e57... 100% ▕██████████████████████████████████████████████▏ 1.7 KB
pulling f1cd752815fc... 100% ▕██████████████████████████████████████████████▏ 12 KB
pulling 56bb8bd477a5... 100% ▕██████████████████████████████████████████████▏ 96 B
pulling e711233e7343... 100% ▕██████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success
>>> Send a message (/? for help) Before running this command, make sure there is enough space on your hard disk. The download time depends on the size of the model and your Internet speed. After it finishes, you will see the Ollama text prompt. Type in any question and see how the model answers it. For example:
>>> What is the capital of Japan?
The capital of Japan is Tokyo.
>>> Send a message (/? for help)How to select the model
Some models will be too large to run on your computer. The llama3.1 has three model files:
| Name | File Size | Minimum configuration |
|---|---|---|
| 8b | 4.7GB | 4 CPU, 16GB RAM, GPU/16GB |
| 70b | 40GB | 8 CPU, 64GB RAM, GPU/45GB |
| 405b | 231GB | 8 CPU, 64GB RAM, GPU/240GB |
I recommend starting with the smallest model. If it works, load the next one, and so on, until your computer overloads and cannot answer your question.
You can find and download other LLM files. In addition to the Llama-based modles, Ollama supports many other formats, including GGUF, Gemma, Phi, etc. To explore models, visit the huggingface.co/models website.
📝 With Ollama running, you can immediately start using all the features of generative AI. You have the option to use either the command-line interface or REST API. If you prefer the web interface, follow the steps 3 to 5 to get started.
Step 3: Install Docker
☕ Skip this step if you already installed Docker on your machine.
Go to the Docker website www.docker.com and download Docker for your OS. Run the installer and select the desired settings. If you have never used Docker before, use the default installation.
Once you have installed Docker, it will start automatically. When you open the Docker application window, you will see a table listing all the containers installed on your computer. Initially, this list will be empty. You can use the Docker application to start, stop, and restart containers.
Step 4: Install Open WebUI
☕ Skip this step if you have already installed the Open WebUI container in Docker.
Go to docs.openwebui.com. Read the instructions carefully. Since you are running Ollama on your computer, use this command to download and run the container:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainThe Docker will download container images from the web and install them on your computer.
Step 5: Run Open WebUI
Open a Docker window and find the open-webui container. If the status is not “Running”,, click run to start the application. The Open WebUI web server is listening on port 3000. Make sure that Ollama is still running (see step 2). Then, open the localhost:3000 web page to connect to the application.
When you open this page for the first time, you will be asked to log in. If you do not have an account, click on the “sign up” link to register. Your login will only be used for authentication. Open WebUI will not send your data to external servers.
After logging in, you will see the main page for Open WebUI. Select the model you want to use: llama3.1:8b. Type your question in the prompt and wait for the response. The Ollama will stream the answer to the web page:
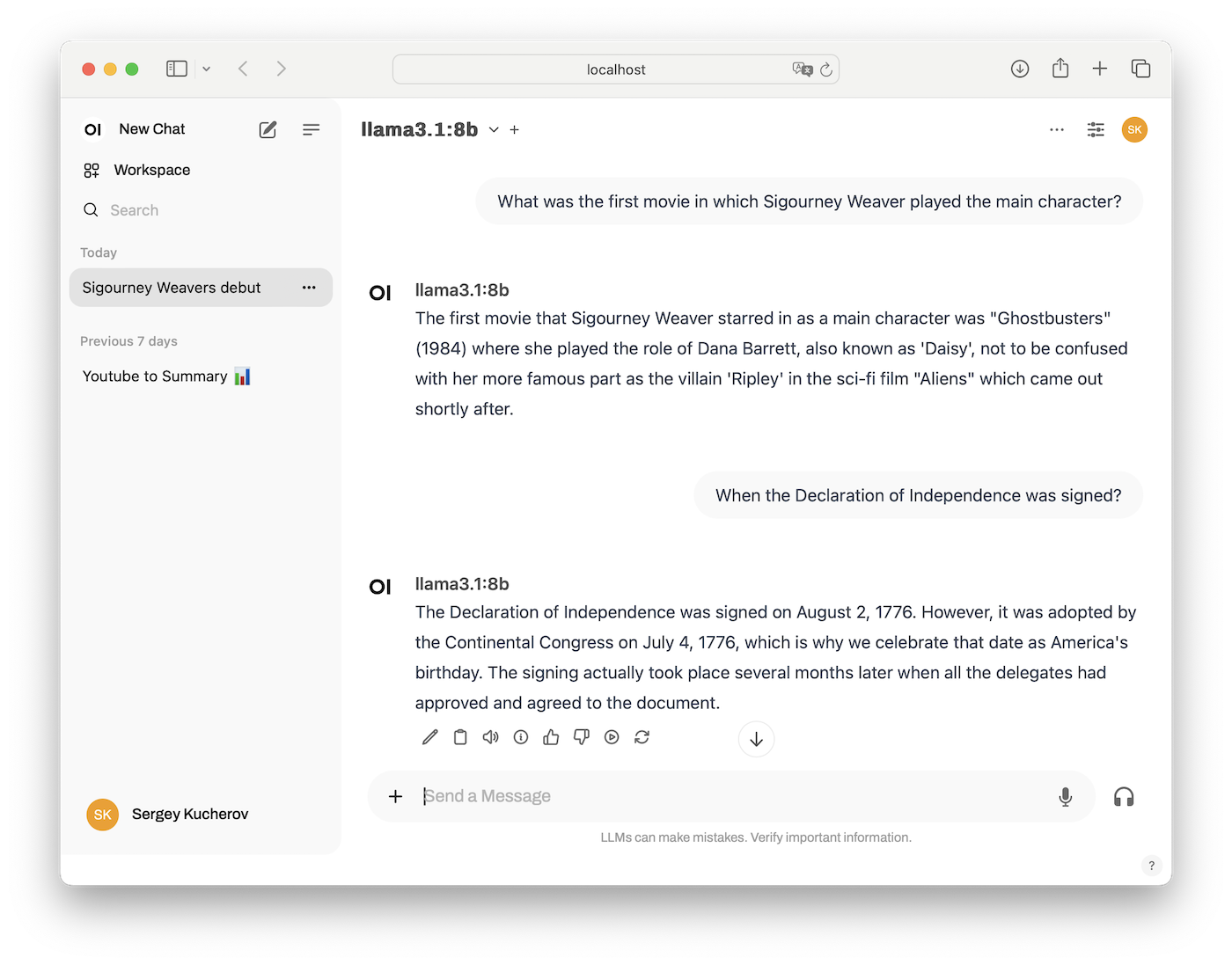
Use Open WebUI
At the bottom of the screen, you will see a touching warning: “LLMs can make mistakes. Verify important information.” The mere fact that someone has to be warned tells you something.
The llama3.1 model contains a wealth of knowledge. However, to get the most value from this program, provide it with specific and unique information that you want to analyze. Use the + sign to the left of the prompt to add a file to your question. A file can contain books, articles, resumes, white papers, technical documentation, source code, or any other information you want to use for your research.
🔒 Since you are running Ollama on your machine, the conversation with AI remains private. Ollama and Web UI do not need to connect to the web. You can turn off your network interface, and the application will work.
Use Ollama REST API
As long as you have Ollama running on your computer, you can access the REST API without the need for Docker and Open WebUI. You can test the REST API using command-line applications such as curl, or an application like Postman or RESTA.
The Ollama REST API uses port 11434. Here is an example of a chat question. Run the following HTTP request:
POST http://localhost:11434/v1/chat/completions
{
"model": "llama3.1",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "When the Declaration of Independence was signed?"
}
]
}You will need to wait for 3-5 seconds to see the response:
{
"id":"chatcmpl-478",
"object":"chat.completion",
"created":1722779146,
"model":"llama3.1",
"system_fingerprint":"fp_ollama",
"choices":[
{
"index":0,
"message":{
"role":"assistant",
"content":"The Declaration of Independence was signed on August 2, 1776,
by 56 individuals representing the 13 American colonies. However,
it's worth noting that the actual signing process took place over several months,
with the document being adopted by the Continental Congress on July 4, 1776.
July 4 is now celebrated as Independence Day in the United States,
commemorating the adoption of the Declaration, but not necessarily the exact date
when all signers signed."
},
"finish_reason":"stop"
}
],
"usage":{
"prompt_tokens":13,
"completion_tokens":96,
"total_tokens":109
}
}The waiting time depends on the size of the model and your computer's specs. The Ollama API also supports a streaming option. Use it if you do not want to wait for the program to finish building the entire response but rather display text as it is generated.
The Ollama API is a versatile tool that can be used to create a custom UI or to integrate generative AI features into your local applications.